【第10回】テキストデータの分析の仕方
- M.N.
- 2020-04-05
※ 『企業と人材』誌(産労総合研究所発行)に、2019年7月号から2020年6月号までの予定で『人材開発部門のデータ活用』を連載しています。誌面だと小さくなる図表を改めて掲載する他、誌面には掲載しきれない参考文献や参考情報を当ウェブサイトにて紹介します(毎月5日の発行日に合わせて公開)。連載本文PDF
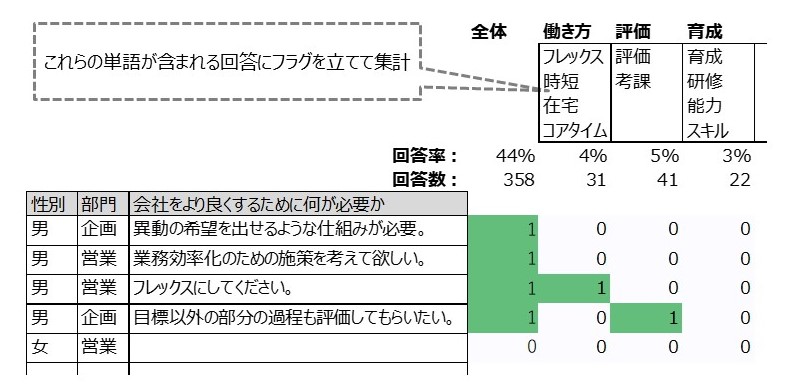
【図1】 簡単なテキストマイニング
【図2】 本格的なテキストマイニング
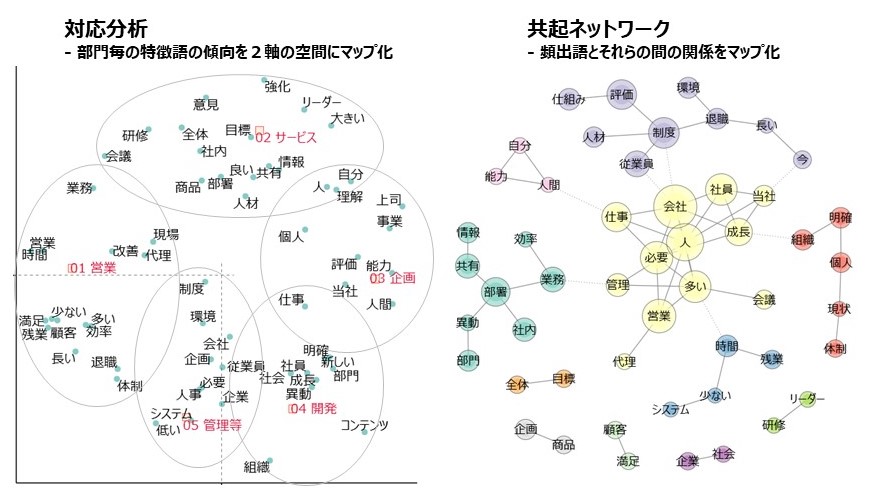
【テキストマイニング(計量テキスト分析)の本質と、多変量解析との関係】
連載本文で述べたように、一つ一つの文章(行やパラグラフ)に、予め取り出しておいた頻出語・重要語が、含まれているか(=イチ)/含まれていないか(=ゼロ)フラグを立てる、図1のような形式の表を準備することが、テキストマイニングの基本であり、土台となります。
文章が1000パラグラフ、計測したい頻出語や重要度が100語あるとすると、そのテキストデータは、1000行×100列のマトリクスとして表現できることになります。マトリクスの一つひとつのセルに、イチかゼロかの値が入ります。そうすると、数値回答データと同じように、「平均点(その単語が含まれている割合)」や「ある単語とある単語の間の相関係数」を計算することもできますし、「目的変数に対する特定の単語の影響力を調べる重回帰分析」や、「多くの単語を少数のグループに集約する因子分析」も実施できることになります。テキストマイニング(計量テキスト分析)とは、出発点となる分析対象は文章であっても、分析手法としては、数値を分析するのと同じ統計分析に他なりません。そのことを踏まえることで、テキストマイニングの議論が理解し易くなります。
【高度なテキストマイニングを行うにあたっての参考書】
KH Coderを活用して高度なテキストマイニングを行うにあたっての参考書を以下紹介します。
まず、再掲となりますが、KH Coderのウェブサイト。
https://khcoder.net/
◆
そして、次が開発者の樋口耕一氏自身によるKH Coderの定本です。KH Coder開発の狙いや、仕様の細かい説明とともに、学術研究における計量テキスト分析の活かし方、実際の研究事例が紹介されています。KH Coderを使って論文を作成した場合にはこちらを文献として明示することが求められていますので、そうしましょう。
樋口耕一 『社会調査のための計量テキスト分析――内容分析の継承と発展を目指して』 ナカニシヤ出版、2014年
◆
ただし、ボリュームも多く研究者向けの記述も多いため、最初の取っ掛かりの本としては次が優れています。KH Coderの最新版であるKH Coder3に基づいて、実際に始めるにあたって必要十分な知識が掲載されています。手法やソフトの使い方についてだけでなく、分析を始める前にどうしても必要になる、テキストデータの整理と調整(データクレンジング)についても触れられています。
末吉美喜 『テキストマイニング入門: ExcelとKH Coderでわかるデータ分析』
◆
次は、原理の説明面でも実施手順面でも、上記の本よりもう一段階深めたものになっています。頻繁に本格的にテキストマイニングを行うことになったらこちらがお勧めです。
牛澤賢二 『やってみよう テキストマイニング ―自由回答アンケートの分析に挑戦!』