【第7回】データ分析の基本1(Step1~3: 現状を可視化する)
- M.N.
- 2020-01-05
※ 『企業と人材』誌(産労総合研究所発行)に、2019年7月号から2020年6月号までの予定で『人材開発部門のデータ活用』を連載しています。誌面だと小さくなる図表を改めて掲載する他、誌面には掲載しきれない参考文献や参考情報を当ウェブサイトにて紹介します(毎月5日の発行日に合わせて公開)。連載本文PDF
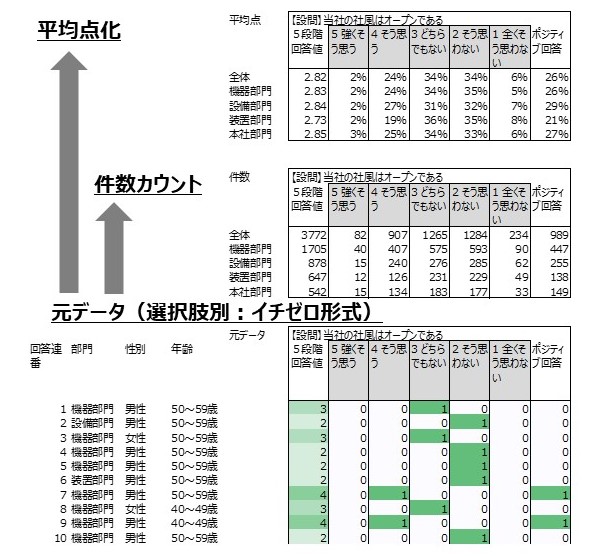
【図1】 設問別・選択肢別の集計
【図2】 設問別の集計
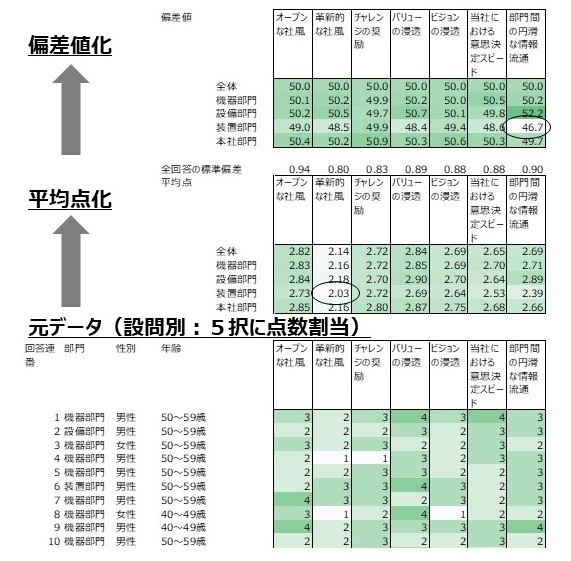
【集計・分析前のデータ整備について】
『企業と人材』誌への連載の今回は、Step1~3、すなわち元データに基礎的な加工を施し、現状を可視化するステップについて述べています。
ここでの最初の工程は、元データを、そこからすぐに様々な情報を引き出せるような形に整備することです。
連載本文に述べていないこととして、最初に全ての回答にしっかりと回答IDまたは連番を振っておくことが大切です。元データからの「トレーサビリティ」を確保することが、データ集計・分析の信頼性を高める上での鍵になります。処理の過程でデータを並び替えたり明らかな入力誤りを修正したりした場合にも、元データと照らし合わせることができるようにしておかなければなりません。また、設問にもしっかりと設問IDを振って設問の追加削除や設問文言の変更を管理することが、回答データを蓄積して経年的に回答傾向の変化を追うために、大切です。
その上で、エラー値やイレギュラーな値のチェック、場合によっては補正を行いますが、それらの作業は「データのクレンジング」とも呼ばれる重要な、しかし地道な工程です。この工程に関するノウハウは、データ整備者の、時に無意識的に遂行される作業習慣として蓄積されていたり、データ分析を組織的に行っている場合にはデータ整備チーム内で共有される作業チェックリストとして蓄積されていたりしますが、参考書はなかなか見当たりませんでした。しかし最近刊行された次の書籍には、題名通り、エラーデータのチェックや補正、そしてエラーの予防に至る、正確な集計・分析の土台となるデータ整備のための知識、ノウハウ、そして心構えが余すところなく述べられており、チェックリストとしても有用です。
村田吉徳 『数万件の汚いエクセルデータに因っている人のための Excel多量データクレンジング』
【平均値、標準偏差、偏差値の本質的な理解について】
データ整備の次の工程は、分析に入る前の基本的な集計を行うことです。連載本文では、最初に「件数カウント」、そして「平均点」「標準偏差」「偏差値」を出すことについて述べていますが、「平均点」はともかく「標準偏差」や「偏差値」については、その概念に親しんでいない方も多いかもしれません。
それらの概念に親しむために、本文で推奨しているように、例えば「標準偏差」という言葉で画像を検索してイメージで意味をつかむことも一つの方法ですが、統計学(確率統計論)の根底をユニークな手法で解き明かす次の本を読むことはお勧めです。統計学の土台中の土台である「正規分布」に焦点を当てて、それが発見された背景、思想的な意味、経済理論や金融理論への影響、「ブラック・ショールズモデル」の原理にまで話まで及ぶものですが、まずは第一章を読むことだけでも価値があります。統計学の根底となる、「平均点」や「標準偏差」や「偏差値」の本質的な意味について、それらの概念が生まれた瞬間を再現するかのように、徹底的にわかりやすく解き明かしており、長く統計に親しむ上での基礎を与えてくれます。
【基礎的なデータ分析手法について】
Step5以降の「高度な統計分析」に関しては、「多変量解析入門」といった形で、主にサイエンティストやマーケッター向けに多くの参考書籍があります。
しかしStep4以前に相当する、集計値の比較分析を中心とするより基礎的なデータ分析のステップについては、企業内のデータ活用実務において比重が大きいにも関わらず、かつ実務上意識すべき多くの重要ポイントがあるにも関わらず、実務家向けの書籍は多くは見当たらず、あっても単にEXCELの使い方の指南書に近いものだったりします。その中にあって、経営視点で目的を持ってデータを分析し、結果を示すとはどういうことか、ということを、基礎的なデータ分析に特化した形で示している、実務家向けの書籍を以下紹介します。
◆
次は、データ分析を積極的に経営に活用していることで名高い、大阪ガスのデータ分析専門部隊による、講座のテキストです。最初の仮説設計、データ整備、基礎的な集計・分析の過程が、演習事例を通じて述べられています。
河村真一、日置孝一、野寺綾、西腋清行、山本華世 『本物のデータ分析力が身に付く本』
本連載で言えばStep4(差から課題を特定する)まで扱われています。(ただし、本連載で活用を勧めている「偏差値」は用いていません。一方、本連載では避けている「有意差検定」の考え方を使い、その計算をサポートするためのツールが提供されています。)
◆
次の書籍は題名どおり、「高度な統計分析」に頼ることなく、集計値の比較分析によって価値を生み出せることを述べているもので、本連載の趣旨とも通じるところがあります。著者はやはり、企業(日産自動車)でデータ分析・活用の実務に携わってこられた人です。
柏木吉基 『統計学に頼らないデータ分析「超」入門 ポイントは「データの見方」と「目的・仮説思考」にあり! 』
こちらも本連載で言えばStep4まで扱っています。そこにおいて、目的変数に対する説明変数の影響(相関)は散布図によって検討する方法をとっています。ただ、散布図による方法だと50個の説明変数があれば50個の散布図を描かなければならないことになってしまいます。その点、同じ著者の次の書籍は、もう一歩踏み込んで散布図の内容を一つの指標に圧縮する「相関係数」を導入することで、多くの説明変数を並べて比較できるようにしています。(なお、本連載(次回Step4~5)で述べる「差の連動性分析」とは、相関係数を使用せずに目的変数と多くの説明変数との相関関係を一度に分析する方法であると言えます。)
柏木吉基 『日産で学んだ世界で活躍するためのデータ分析の教科書』