【第9回】データ分析の基本3(Step6~7: アイデアを創造する)
- M.N.
- 2020-03-05
※ 『企業と人材』誌(産労総合研究所発行)に、2019年7月号から2020年6月号までの予定で『人材開発部門のデータ活用』を連載しています。誌面だと小さくなる図表を改めて掲載する他、誌面には掲載しきれない参考文献や参考情報を当ウェブサイトにて紹介します(毎月5日の発行日に合わせて公開)。連載本文PDF
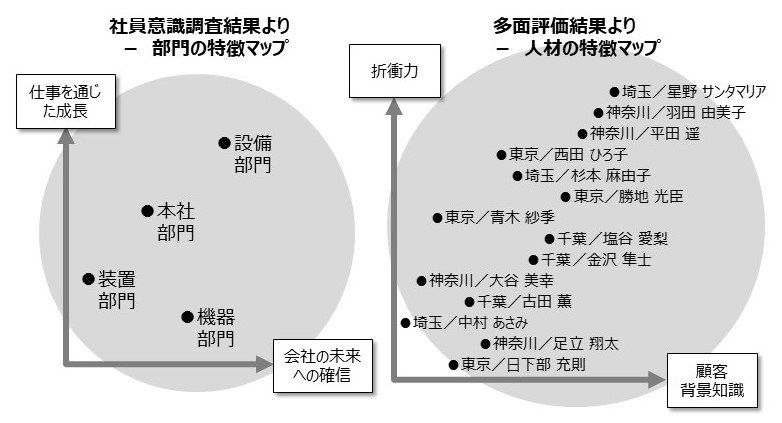
【図1】 人と組織(部門)のマップ
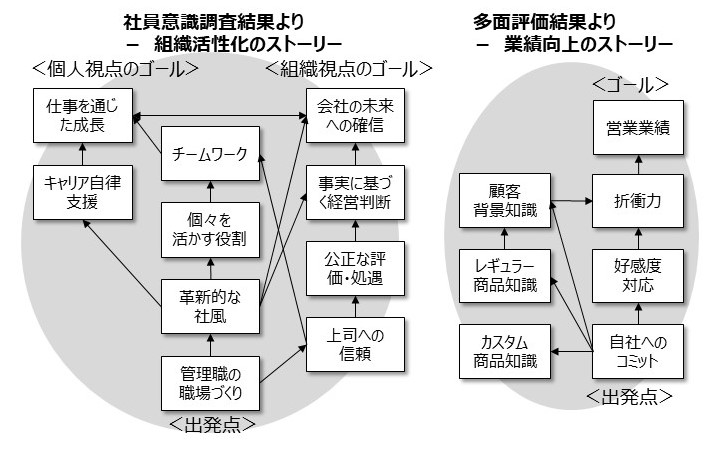
【図2】 成功へのストーリー
【多変量解析の参考書】
本文で触れている重回帰分析、因子分析、共分散構造分析を含む多変量解析手法に本格的に取り組みたい場合、統計ソフト(エクセル統計)の解説Webサイト以外にも多くの参考文献がありますが、原理も実務での使い方もよくわかる、というものは多くはないように思います。もっとも重回帰分析については、西内啓氏の入門書がその要請を満たしてくれている、ということは前回述べました。そこで、重回帰分析以外について参考書を探す必要があります。
その中で、常に終始一貫して実務家(文系ビジネスパーソン)(主にマーケッター)向けに定評ある「入門書」を著している朝野熙彦氏の著作はお奨めできます。すなわち、長年定評があり近年文庫化もされた、
朝野熙彦 『入門 多変量解析の実際 Math&Science (ちくま学芸文庫) 』
そしてその続編としての、
朝野煕彦、鈴木督久、小島 隆矢 『入門 共分散構造分析の実際』
です。実務での活用事例や実践上の注意点(トラブルシューティング)に焦点を当てている一方で、理論面からも数式を用いて手法の意味を完全に説明するものとなっています。数式での説明の仕方には一貫した工夫とポリシーがあり、それは、シグマ記号でなくベクトル記号を用いた表現によって、数式表現を簡略化するとともに図形的な理解とも結びつきやすくしている点です。
もっとも、「誰にでも絶対にわかる」と宣言されていながら、数式に入ると一般のビジネスパーソンの読者を困惑させたりはします・・・が、それでいったん落ちこぼれたからといって、その先を読めないようにはなっていませんし、そして最終的には理解が可能なものであることは、多くの読者の長年の評判が裏づけています。そして、重鎮でありながら今なお、新しい分野(ベイズ統計学等)の入門書も手掛けてもおられますし、西内啓氏と並ぶビジネスパーソンの統計学習のグルとしてフォローすることもよい方法かもしれません。
(いずれにしても参考書選びの原則としては、著者一人ひとり背景やスタイルが違いますので、様々な著者の様々な参考書に手を出すよりは、依拠する著者を決めたら、できるだけその人の著作を通じて学習する、というのが賢い学習のスタイルであると言えるように思います。)
◆
その他、次の書籍は、徹底的な理解が得られる統計学習の鉄板本としての評価が高く、実際、数式を書き写しながら一行ずつ根気強く追っていけばかならず読み進めることができるし本質の理解に至ることができる、ということを感じることができます。ただ、フルタイム在職中のビジネスパーソンがその時間的/心理的余裕を持てるケースはなかなかないとも感じます。
下記は上記教科書に基づくワークブックで、上記書籍の要点整理的な位置づけともなっています。
南風原朝和、杉澤武俊、平井洋子 『心理統計学ワークブック―理解の確認と深化のために』
【多変量解析の種類について】
多変量解析の概説書を開けると(あるいは統計ソフトの多変量解析のメニューを開けると)多くの場合、カタログのように多くの手法が並んでおり、圧倒されます。この背景には、手法それぞれ、異なった分野・背景のもと、異なった開発者により、固有の用語法を保ちながら開発・応用されてきたために、今さら不用意に統合するわけにもいかず、並列的にカタログに載せられているという事情もあるように思います。多くの手法は内容的にはお互いに重複を含んでいますので、(たとえば、数量化理論Ⅰ類、Ⅱ類、Ⅲ類はそれぞれ、回帰分析、判別分析、因子分析に相当したりしますので、)手法の種類の多さを気にする必要はありません。今扱っている目的に向けては、連載本文に示した「重回帰分析」と「因子分析」でほとんどの場合十分です。
なお、本文では触れていない多変量解析手法でもう一つ有用なものをあげるとすれば、「クラスター分析」です。「似たものを寄せてグルーピングしていく」という比較的シンプルでわかりやすい手法なので、いろいろな使い道があります。因子分析のように、多くの設問項目(データの「列」方向)を数個の「因子」に縮約するために用いることもできますが、多くの場合、対象となる人や組織(データの「行」方向)をグルーピングするために用いられます。その際、回答の元データではなくいったん因子分析を行って回答値を因子得点化したものをインプットにすれば、「誰がどの因子に強いタイプなのか」といった見地からグルーピングできます。また、元データをインプットにするのではなくStep2で作成した集計表をインプットにして、似た傾向を持つ属性をまとめるために用いることもできます。これにより例えば、「20歳台とマーケティング部門」、「30歳台と営業部門と男性」、「40歳台と女性」がそれぞれ似た傾向を持つグループになっていますよ、といったことを客観的に言うことができます。このようなまとめを行うことで、施策を打つ対象を細分化しすぎることなく、「このグループにはこのような施策群」といった施策のパッケージを整理しやすくなります。
【人工知能と多変量解析】
次元を縮約する因子分析は、人工知能を理解するにあたっても踏まえておきたい考え方です。次は、日本における人工知能の第一人者による一般読者向けの入門書ですが、人工知能の原理を中心に据えており、人工知能の発展をもたらしたディープラーニング技術の核である「特徴表現学習」と、(本連載で紹介する因子分析に相当する)主成分分析とが近いものであることが、わかりやすく説明されています。